Let’s talk AWS CodeDeploy Deployment Configuration. If you’ve ever tried to deploy to AWS using CodeDeploy, you’d notice that you have the option to change the “deployment configuration”. This attribute specifies how CodeDeploy decides to deploy your application and the pass criteria for the deployment.
The three built in options are:
- OneAtATime (default)
- AllAtOnce
- HalfAtATime
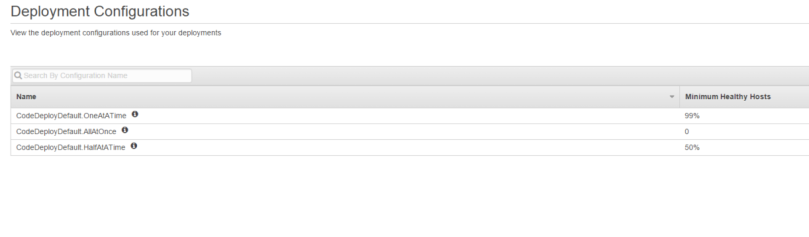
In most cases, OneAtATime works just fine. It deploys your application to one server at a time, and ensures that all* of your installations are successful. I haven’t tested this myself though, but if you have 100 instances, and it probably accepts that one instance can fail.
However as most of us do where we do want to do deployments in scale, speed becomes sort of important. If you have 20 instances to perform an installation to in a blue/green strategy approach then the speed of your deployment increases in a linear scale of n * t, where n is number of servers and t the time to deploy to a single instance. In a nutshell, it’s slow as hell in an enterprise environment.
So, how about let’s decide to deploy AllAtOnce? It solves the problem of scale, given that it triggers all deployments at once, so the time it takes is only as slow as the slowest instance installation. A closer look at the minimum required healthy host is 0 on the board. Which means, CodeDeploy will classify your installation is successful as long as one of your instance installations succeeds. Worst case scenario you can have 999 of your 1000 instances fail on installation and CodeDeploy still thinks the installation is good.
This has many fatal consequences, chief among those is that CodeDeploy will only execute deployments on “last pass”, which in this case it will deploy a poisonous installation on scaling up causing more havoc.
Okay, maybe let’s take the halfway house where half of instance pass with HalfAtATime? Possibly if it successfully installs on half of the instances then it should be fairly good anyway. In theory this works well, as in most cases, your installation should either fail or pass on most with a few rogue instances going south for unrelated reasons. You at most only double your installation time, which is very much in the acceptable range.
Not so fast, what happens when you have only one instance? How does it work half of one? You’d think simple! It should just pass on one … right? You’d be wrong, it doesn’t even try.
Deployment config requires keeping a minimum of 1 hosts healthy, but only 1 hosts in deployment
So HalfAtATime just blatantly does not work if you have a scale of one (perhaps some time during midnight where traffic is low). Again, non-usable scenario.
Helpfully, Amazon has provided several ways you can specify your own deployment config. But hold on, once you look into the details of the request call, you’d find this
{
"value": integer,
"type": "HOST_COUNT"|"FLEET_PERCENT"
}
Wait, you can only specify the minimum host count or fleet percent as a parameter and AWS then over helpfully figures out the deployment strategy for it? Amazon always deploys the amount in the figure rounded down first.
Okay, so what happens when you specify FLEET_PERCENT as 100?
A client error (InvalidMinimumHealthyHostValueException) occurred when calling the CreateDeploymentConfig operation: The value for the minimum healthy hosts with type of FLEET_PERCENT should be positive and less than 100
Damn, how about 99%?
It’ll work fine, until you deploy …
Deployment config requires keeping a minimum of 2 hosts healthy, but only 2 hosts in deployment.
This alternative is worse than HalfAtATime.
Oh so there is NO good deployment configurations possible. Cheers Amazon!
Is there a moral of the story in this article? Consider all your options before diving in for CodeDeploy. This is just one long list of flaws associated with it.
Update (12/01/2016):
I’ve gotten a definitive reply from AWS technical support and here’s what they said:
Hello,
Thanks for your patience, I have got clarification on how FLEET_PERCENT works and it is actually rounded up to the next integer, so you were right if FLEET_PERCENT is set to 99% then 100 instances are needed. However if you use 95% the deployment will succeed just with 20 and 90% with 10. Essentially values above 90% increase the minimum number of instances very fast, but with numbers up to 90% the minimum number of instances stays at relatively moderate numbers of instances.
I did miss this on my previous message but this is actually mentioned on our public documentation[1], please accept my apologies for the misleading comments I provided in my previous message.
Please let us know if there is anything else we can help you with.
References:
[1] http://docs.aws.amazon.com/codedeploy/latest/userguide/host-health.html#host-health-minimum
Sounds a bit iffy. I am not sure if I’d ever design a system with this sort of qualifier but there you go.
